The search engine I built and shut down

Earlier this year, I built a website called Find That Wine because I had a very specific itch.
In Norway, where I am from, wine is centralized through Vinmonopolet. That comes with a long list of political, cultural, and practical tradeoffs, but from a consumer perspective it has one very convenient side effect: discovery is easy. If you want to know whether a wine is available, who imports it, what it costs, and where it can be picked up, there is only one obvious place to look.
Denmark, where i currently live, is different. There is no wine monopoly. The market is more open, more fragmented, and in many ways more exciting. Independent shops, small importers, niche webshops, auction platforms, and specialist stores all coexist. That is part of what makes the Danish wine scene interesting. But it also makes discovery harder.
If you are looking for a specific producer, vintage, grape, region, or bottle, you often end up searching shop by shop. You might check one webshop, then another, then a few importers you remember from Instagram, then a private marketplace, then maybe a PDF price list somewhere. If you are lucky, you find what you were looking for. If you are not, you never know whether the wine was unavailable or whether you simply searched in the wrong place.
Find That Wine was my attempt to solve that problem.
The idea was simple: gather publicly available wine listings from Danish wine shops and present them in one searchable interface. The site would not sell anything. It would not take a commission. It would not try to become a marketplace. It would simply help people discover where wines were available, then send them directly to the shop that had the bottle.

In theory, everyone wins. Consumers find wine faster. Shops get more organic traffic. Smaller importers become easier to discover. Public product data becomes more useful.
In practice, the project became more complicated than that.
This post is a retrospective on what I built, how it worked, what I learned from building most of it with Codex as an assistant, and why I eventually decided to shut it down.
The problem: Denmark has abundance, but not one index
The Danish wine market has a lot of charm precisely because it is not centralized. There are serious specialist shops with deep Burgundy allocations, natural wine importers with tiny producer portfolios, auction listings, private collections, Italian specialists, Austrian specialists, Champagne shops, hybrid bottle shops, and plenty of small webshops with their own angle.
That diversity is good. It also means the market does not have one shared discovery layer.
If you know exactly which shop imports a wine, the problem is easy. You go there. If you know the importer behind a producer, the problem is still manageable. But if you only know the wine, or if you are exploring a category, the work shifts to the consumer.
I kept running into questions like:
- Who has this producer in Denmark?
- Is this bottle sold out everywhere, or just at the shop I checked?
- Which shops carry what im looking for?
- Is an auction listing the only place this bottle appears right now?
These are not exotic questions. They are normal consumer questions. The frustrating part was that the answers often existed in public, just scattered across many websites.
So the project started with a consumer-first assumption: if the data is already visible on public shop pages, then a search engine that points users back to those shops should be useful.
That assumption carried the project technically. It did not fully carry it socially or legally.
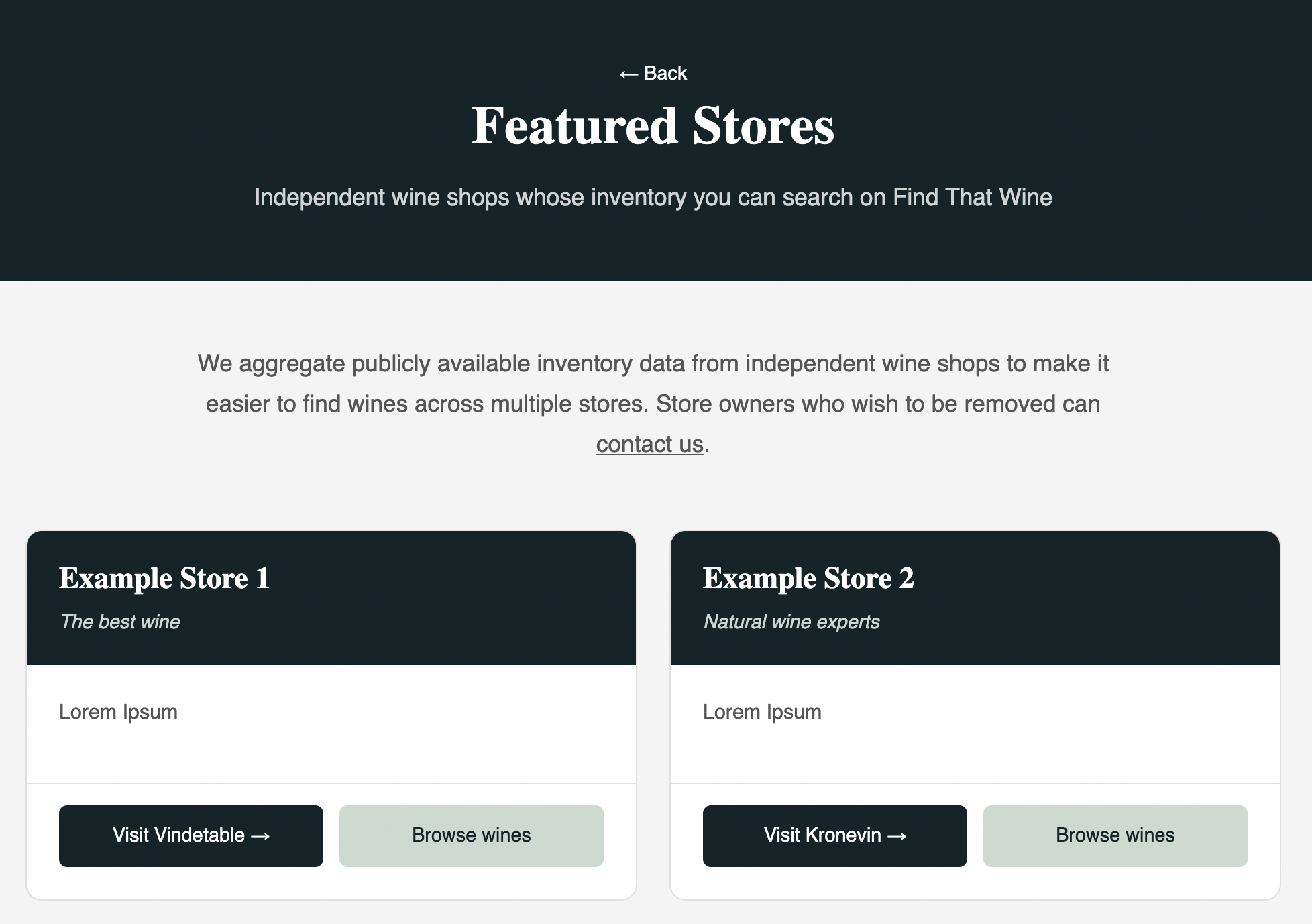
What the site was meant to do
The product goal was deliberately modest.
Find That Wine was not meant to be a Danish Wine-Searcher clone with subscriptions, merchant dashboards, price history, paid placement, or lead generation. I wanted something smaller and more direct:
- Load inventory from Danish wine shops.
- Normalize the listings into one shared format.
- Let users search across all stores at once.
- Let users filter by store, producer, category, tags, stock status, and price.
- Show enough information to evaluate a result.
- Link directly to the seller for purchase.
There was no checkout. No basket. No payment flow. No margin. No affiliate tracking. No advertising model.
The site was free because the point was not to earn money. The point was to make life easier for consumers aka myself and, ideally, send better-qualified traffic to the wine shops.
That was the optimistic version of the project: a public, neutral discovery layer for Danish wine.
Normalize everything
The core technical problem was not rendering a search page. It was making different sources look similar enough that one search page could work.
The project used a simple normalized item model. Each listing became a flat object with fields such as:
type NormalizedItem = {
storeId: string;
storeName: string;
storeBaseUrl: string;
productId?: string | number;
productTitle: string;
vendor?: string;
productType?: string;
tags?: string[];
variantId?: string | number;
variantTitle?: string;
sku?: string;
price?: string;
available: boolean;
inventoryQty?: number | null;
productUrl?: string;
imageUrl?: string;
updatedAt?: string;
};
This was not a perfect wine data model. It did not properly separate producer, cuvee, vintage, region, appellation, grape varieties, bottle size, farming, importer, scores, or allocations. It was a pragmatic model for a hobby project: enough structure to search, filter, sort, and link out.
That flat model turned out to be one of the better choices in the project. It made ingestion easier. Shopify products, scraped HTML listings, and parsed PDF rows could all become the same shape. It also made the frontend simple because it could treat every product as one list item regardless of source.
I had a more ambitious data model in mind. It imagined separate source entities, product entities, wine-specific attributes, variants, traceability, categories, regions, grapes, certifications, and so on. That would be the better long-term model. But it would also require much better source data than most public webshop listings provide.
For the version I actually built, the flat model was the right compromise.

Open Shopify APIs was a game changer
The project became realistic because many Danish wine shops use Shopify.
Shopify exposes product data through a public products.json endpoint on many stores. For a hobby project, this is almost dangerously convenient. You can request a store's products, paginate through them, normalize them, and cache them as JSON.
In the end i had configured more than thirty configured sources, including Shopify shops and custom scrape sources.
A scheduled job fetched Shopify stores, requested /products.json?limit=250&page=N, normalized every variant, and wrote the output to JSON files.
I even tried to be nice about it:
- The fetcher used a custom user agent identifying the project and contact address.
- It supported retries.
- It handled HTTP 429 rate limits with backoff.
- It waited between pages.
- It capped pagination to avoid runaway scraping.
- Only one run per 24 hours
- Respect robots.txt
This was the part of the project that felt cleanest. A scheduled job could refresh data periodically, the frontend could load cached JSON, and users got fast search without each query hitting every shop.
For shops already on Shopify, the integration required no custom partnership and no invasive data access. The same public product data that powered their storefront could power discovery.
But that convenience also created one of the central tensions: just because something is publicly reachable does not automatically mean every shop wants it aggregated, cached and displayed somewhere else. Which is fair. Its their livelihood after all.
But not every source looked like Shopify
The more interesting wine sources were not always Shopify stores.
The project had several custom ingestion paths for sources that did not expose a neat product feed. Some sources were ordinary web pages. Some were auction listings. Some were PDF price lists. Each of them needed a slightly different way of turning public information into structured search data.
For HTML pages, the scraper looked for repeated product or listing blocks and pulled out whatever useful fields were available: titles, prices, links, images, stock signals, seller information, colors, vintages, and auction status when relevant. The exact markup varied from site to site, so the scraper had to be written around the structure of each source rather than around one universal standard.
Some pages hid surprisingly useful data inside attributes or embedded JSON used by the webshop itself. In those cases, the scraper could extract cleaner product information than what was visible in the rendered text. Other pages required more basic parsing: reading category pages, following pagination, inferring product type from the section of the site, and deduplicating products that appeared in more than one category.
PDF lists were a different beast. Some importers and specialist shops still publish their assortment as a document rather than a webshop catalog. The parser tried to read those lists, identify producer names, regions, certifications, vintages, prices, grape varieties, bottle sizes, and product types, then turn the result into the same normalized JSON format as every other source.
This was fun engineering because every source was a small puzzle.
It was also fragile engineering. HTML changes. CSS classes change. Embedded tracking payloads disappear. PDF layouts shift. Product type labels vary from shop to shop. A scraper that works today can quietly produce poor data tomorrow.
A deliberately simple frontend
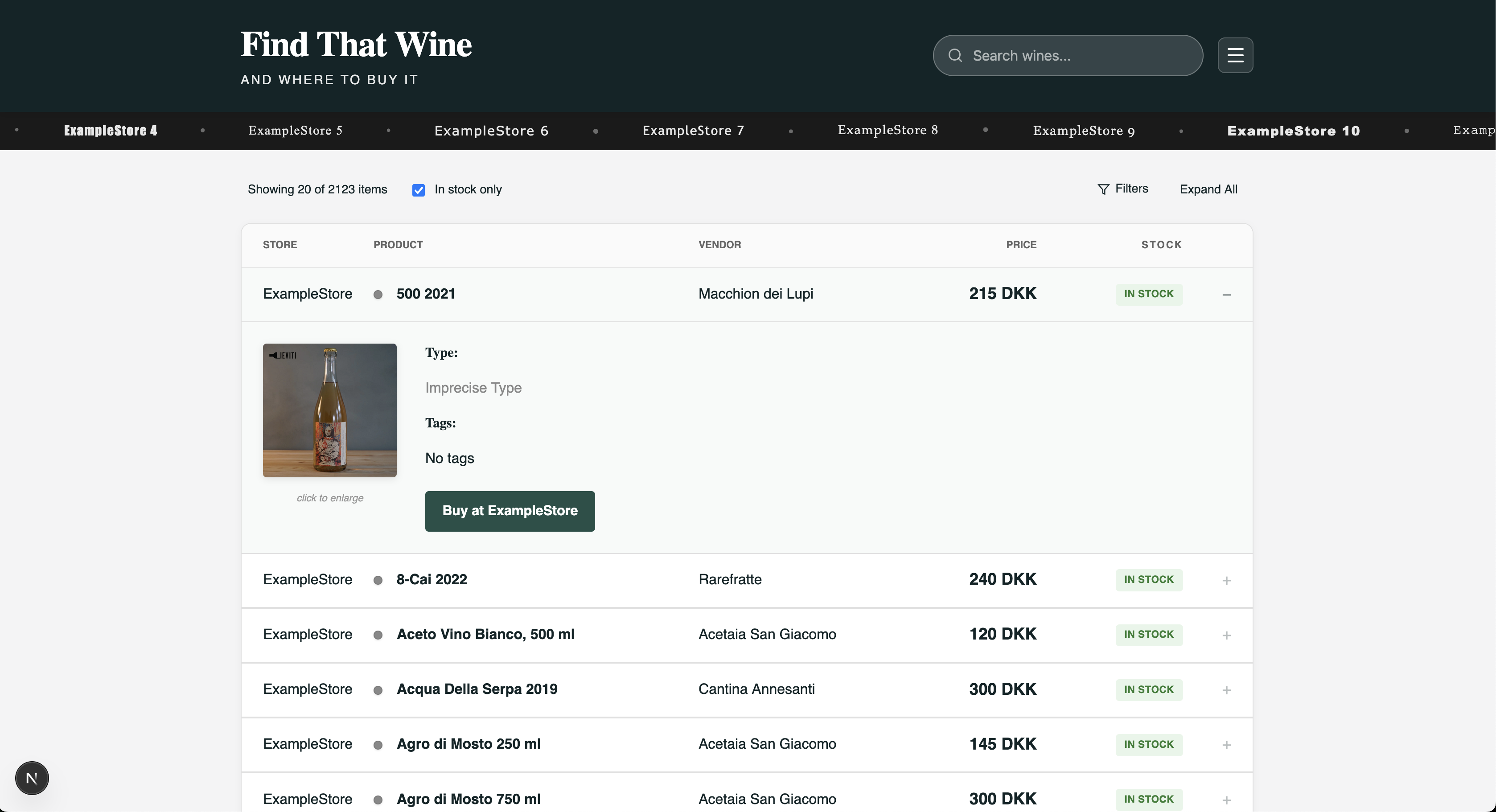
The main user interface was a Next.js app using the App Router, React, and TypeScript. The architecture was intentionally simple: load all visible store data into the browser and filter client-side.
That sounds naive, but it worked for this scale. For a niche wine search tool, sending cached JSON to the browser and filtering client side was doable. It avoided building a search backend, database schema, hosted index, or API query layer before I knew whether the product should exist.
The search page did several useful things:
- Loaded the store manifest first.
- Loaded visible stores in parallel.
- Sorted initial store loading by file size so smaller stores appeared quickly.
- Built facets for vendors and tags client-side.
- Filtered by store, vendor, tags, product category, price range, stock status, and text query.
- Sorted by price, store, product, or vendor.
- Stored filter state in the URL.
- Expanded rows to show images, tags, product type, and outbound purchase links.
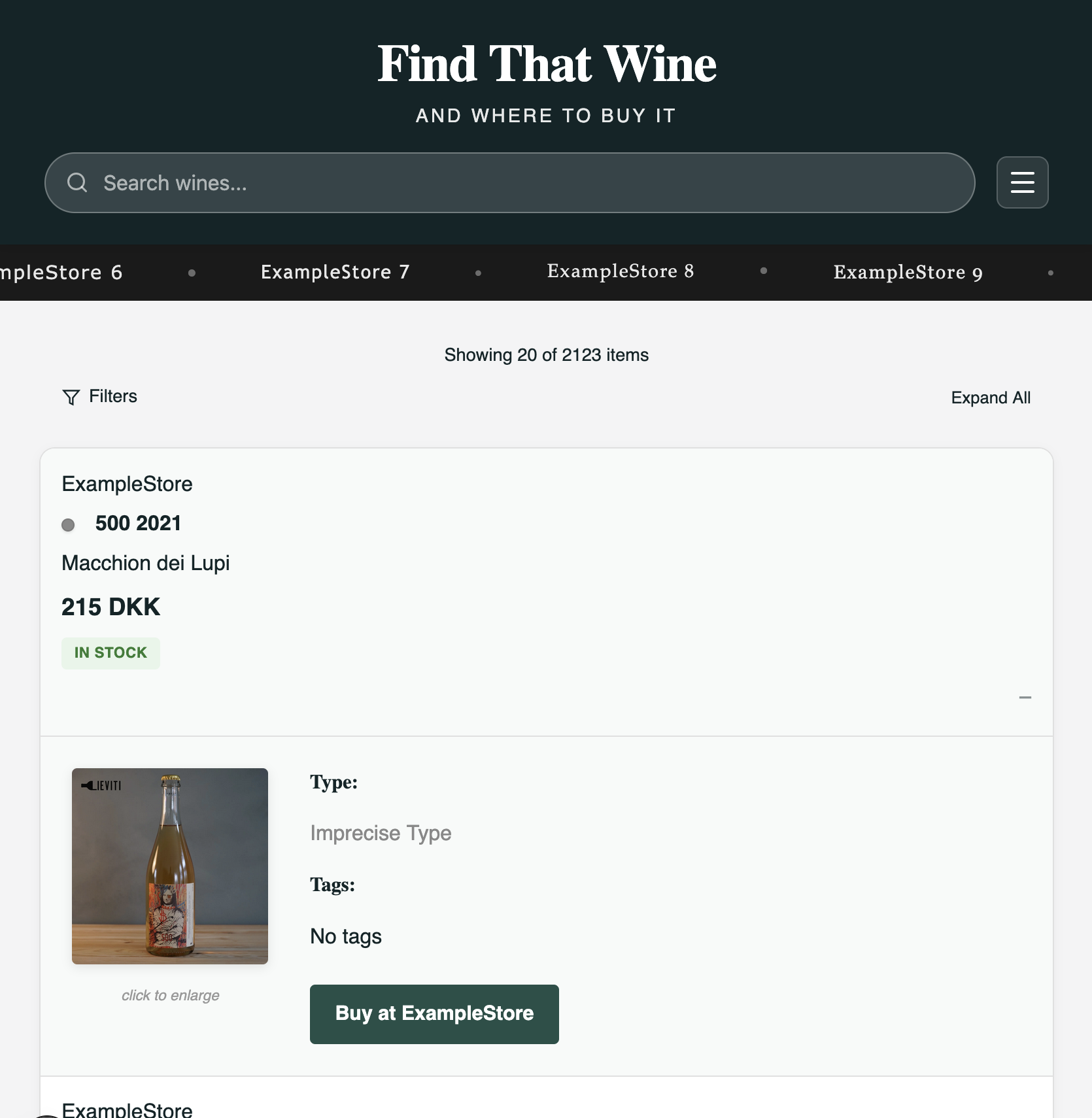
The row design was intentionally utility-focused. A result showed the store, product name, vendor, price, stock state, and category. Clicking expanded it. Available images were lazy-loaded from the upstream source only after expansion to avoid loading a large number of bottle photos unnecessarily.
The site treated different source types slightly differently in the stock badge. Normal webshop products showed in stock or sold out, auction-style listings were marked as auctions, and document-based entries were marked as coming from a parsed list.
It was not an advanced search engine, but it worked!
Categorization is hard work
Wine data looks structured until you try to combine it.
One store might use Rødvin. Another might use red wine. Another might use Naturvin, which is not a color. Another might use a region like Bourgogne as the product type. Another might put important information only in tags. Some stores sell beer, spirits, cider, glassware, gift cards, subscriptions, tastings, olive oil, books, and accessories alongside wine.
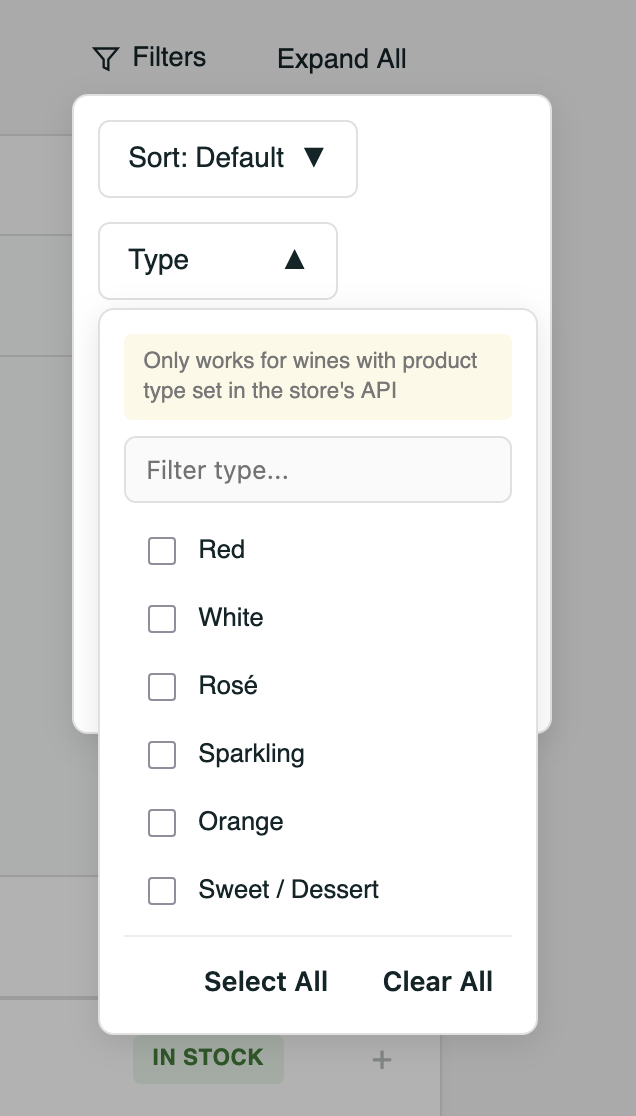
The project had a product category configuration mapping raw product types into normalized categories:
- Red
- White
- Rose
- Sparkling
- Orange
- Sweet / Dessert
- Fortified Wine
- Sake - Umeshu
- Spirits
- Beer
- Cider
- Non-Alcoholic
- Imprecise Type
It also had an exclusion list for things that should not appear as wine search results such as gift cards and accessories.
It was a boring job to sort through endless amount of product type strings, but without doing it the search became polluted with vouchers, tasting events, and product bundles. The biggest problem was that every new store introduced new product type strings and every new string needed to be mapped or excluded.
The app even had product type monitoring. A nightly analysis could detect unmapped product types and expose it as metrics i could act upon.
That is a good example of how the project slowly became more serious than the original idea. I started with "search some wine shops" and ended up with category mapping, cache diagnostics, cron jobs, ingestion APIs, monitoring, and admin controls.
Data is messy
Very early on it became clear that i needed more than json files to debug and administer the sources. The data ingestion needed supervision.
The portal was plain, but it supported:
- Checking whether each store had cached data
- Seeing item counts and last update times
- Forcing a refresh for a single store
- Refreshing all stores
- Adding, editing, and deleting store configs
- Toggling store visibility
- Inspecting sample products
- Viewing directory contents and diagnostics
- Running product type analysis
European infrastructure
One infrastructure decision I cared about was keeping the project in Europe.
This was not because the application was technically complicated. It was a small website with cached product data, scheduled updates, and a few admin tools. It could have been hosted almost anywhere. But the project was about Danish wine shops, Danish consumers, and public data from the European market. For that reason, and that the US threatened to invade Greenland at the time, I wanted to keep things in Europe.
European infrastructure was also a way of keeping the project honest about its scope. This was not a global platform. It was not trying to optimize for the cheapest possible hosting or the most aggressive growth setup. It was a local tool for a local market. The infrastructure should reflect that.
On that note, i built it using an American AI, so that promise was quickly broken.
Building with AI
Most of the coding was done with help from Codex, just ever so slightly guided by my own knowledge of SWE and by the concrete problems I wanted to solve.
I know the domain. I had opinions about what the product should do. I could read code, test behavior and ask for changes. Codex helped produce much of the implementation: Next.js pages, scraper modules, normalization logic and anything else i could imagine.
This made the project possible in a way it probably would not have been for me a few years earlier.
But AI assistance did not remove the need for judgment or manual intervention along the way. I am an engineer after all.
The uncomfortable questions
The code was not the reason I shut the project down.
The project had bugs and rough edges, but nothing about the implementation was impossible. The bigger issue was that I could not get comfortable with three questions.
1. Am I breaking any laws?
I am not a lawyer, and this post is not legal analysis.
But the question mattered. The site aggregated public product listings from shops, cached them, normalized them, displayed them in a different context, and linked back to the original sellers. That sounds harmless from a consumer point of view, especially when the data is already public and the site sends traffic back.
But "publicly visible" and "free to republish in aggregated form" are not the same thing.
There are possible questions around terms of service, database rights, copyright in product descriptions or images, robots.txt expectations, rate limits, commercial impact, and whether a shop has consented to being indexed this way. Even if the project is non-commercial, it still creates a copy of data and presents it as part of another service.
I tried to be as respectful as i could. The site cached data instead of hammering stores on every user search. It used an identifying user agent. It linked back to shops. It did not sell the products itself. It documented integration formats and invited shops to get listed or taken off the site.
Those choices and considerations help, but they do not answer the legal question.
2. Will this hurt my relationship with importers and stores?
This question bothered me more than the purely technical ones.
The Danish wine scene is not a faceless market of commodity sellers. It is a network of small shops, importers, enthusiasts, and relationships. Many of the most interesting bottles come from people who care deeply about producers, allocations, customer trust, and how wines are presented.
From my perspective, Find That Wine was meant to help those shops. It could make their bottles easier to find. It could send them customers who were already looking for something specific. It did not take a commission or try to sit between them and the buyer.
But intent is not the same as perception.
A shop might see the site as helpful. Another might see it as scraping. Another might dislike price comparison. Another might worry about stale stock information. Another might not want certain products indexed because allocations are sensitive. Another might object to product images or metadata being displayed outside their own site. Another might simply prefer to be asked first.
All of those reactions would be understandable.
There is also a difference between "this is technically possible" and "this is polite." In a community that depends on trust, being polite matters.
3. Is the Danish market open to this idea?
The third question was product-market fit, but not in the startup sense.
I did not need the site to become a business. I did not need revenue. But I did need the market to tolerate the idea.
A search platform for wine sounds obviously useful to consumers. It is less obviously welcome to sellers.
Price transparency can be uncomfortable. Aggregation can flatten the differences between shops. A wine that one importer presents with context, producer story, and allocation logic can become one row in a table sorted by price. A store's carefully designed website can become just another data source. A bottle with limited availability can be discovered by people outside the intended customer base.
In Norway, a centralized monopoly creates a centralized search experience almost by default. In Denmark, the absence of a monopoly means the search layer is not neutral. Whoever builds it makes choices: which shops to include, how to rank results, what fields matter, whether price is prominent, how stale data is handled, and whether sellers consent.
I was not sure the Danish market wanted a hobbyist-built version of that.
Why I shut it down
I shut the project down because the unresolved social and legal questions outweighed the utility of keeping it live.
That may sound anticlimactic, especially after building all the machinery: scrapers, category mappings, PDF parsing, monitoring, data models, and a fairly usable frontend.
But it also felt like the responsible decision.
There is a seductive moment in many software projects where the technical system starts working and you want that to be the finish line. Data flows in. Filters work. Pages load. The admin dashboard shows green checks. It becomes tempting to say: the project is real now.
But it being real does not mean it is right.
Find That Wine solved a real consumer problem. I still believe that. I would personally use a trustworthy version of it. I think many Danish wine consumers would too.
But the trustworthy version probably needs clearer participation from shops and importers. It needs a stronger legal basis. It needs better data agreements, a better opt-out or opt-in process, and a more careful stance on product images, stale availability, and price presentation.
What I would do differently
If I were starting over, I would change the order of operations.
Technically, I started with the data because that was the exciting part. Find shops, fetch products, normalize data, build search. That is a natural builder instinct.
But the better path would be:
- Talk to shops and importers first.
- Ask whether they want this kind of discovery tool.
- Ask what concerns they have.
- Offer an opt-in data feed format.
- Start with fewer sources but explicit participation.
- Treat scraping as a fallback, not the default.
There is a version of this project that could be sustainable. It would be slower, more relationship-driven, and probably less comprehensive at launch. It would ask shops to participate. It would give them control over how their inventory appears and it would clearly explain data usage.
It would avoid surprises.
The part I still like
The product idea is great.
I like the idea of being able to search across the Danish wine scene without already knowing which shop to check. I like the idea of small importers becoming more discoverable. I like the idea of a consumer tool that sends traffic directly to shops instead of trying to own the transaction.
I also like the technical shape of the project. It was appropriately boring in many places:
- Next.js and React for the UI.
- JSON files for cached data.
- A flat normalized item model.
- Cron-based updates.
- Client-side filtering.
- Simple admin diagnostics.
- Scrapers only where structured sources were not available.
FIN
Find That Wine ended as a working prototype.
It could aggregate Shopify stores. It had custom scrapers. It could parse PDF wine lists. It had a data model. It had a searchable frontend. It had filters, categories, price ranges, stock states, and outbound product links. It had admin tools and monitoring. It had documentation for store onboarding and data formats.
But it was not enough for me to feel comfortable keeping it online.
That is probably the main point of this retrospective: technical feasibility is only one part of a product.
As builders, especially with AI tools, we can now create working software faster than ever. That is genuinely exciting. But the speed can make it easy to skip the slower questions:
- Who is affected by this?
- Who has consented?
- Who might object?
- What assumptions am I making about public data?
- What relationships could this change?
- What responsibility do I take on by keeping it running?
For Find That Wine, those questions did not have answers I was satisfied with.
So I turned it off.
I am still glad I built it. It taught me a lot about scraping, handling unstructured data, search interfaces, operational tooling, and AI-assisted development. It also taught me that sometimes the responsible end to a project is not scaling it, monetizing it, or polishing it.
Sometimes the responsible end is writing down what you learned, shutting the server down, and leaving the idea in a better state for the next attempt.