Chaos engineering in practice - Do you need multicloud redundancy?
Recently i gave a talk at the Cloud Native Day in Bergen about Chaos Engineering titled “Chaos engineering in practice - Do you need multicloud redundancy?”.
I thought it was a fun talk and since we sadly did not record the talks, I figured that I should write a blog post instead! I already have a script (although written in Norwegian) to accompany the presentation, so why not translate it and publish most of the contents here?
Here goes!
Welcome to this written version of my talk!
Pic by Håkon Broder Lund

My name is William (dahlen.dev - dev), and while typing this i work as a Lead Platform Engineer at Telenor Norway where we have the task of creating the world’s best developer experience through our efforts with self-service, automation and building resilient platforms.
I have been working as a sysadmin since 2013, where the last few years have been spent on the cloud side of things. I have a passion for modern service development, especially infrastructure as code/data and making life simpler.
Chaos engineering as a subject is not something i have practiced much myself, at least not out of free will. It has however always fascinated me, hence this talk.
What is Chaos Engineering?
I like using the wikipedia definition when describing new concepts, not because its always right, but it is an equalizer; everyone has access to it and you don’t need to dig deep into books to find “the correct” one.
Chaos engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Its short and sweet. We are exposing a system to turbulent conditions to see how it reacts. This is done to build confidence in the system’s capability to withstand turbulent conditions in production.
This is not revolutionary. We have been doing this in the tech industry since the eighties, but its not until Netflix introduced it to their platform during their big cloud migration project in 2011 that it got wind in its mainstream sails.
Personally I did not know about the concept until a few years ago, and even then I was not sure how I should approach it. I am sure most people are in the same boat, so i won’t go to deep into chaos engineering, but we will look at one example of the tech enabling it. In addition I will present a few core concepts I believe are important in building a culture for embracing failure and modern system development. Finally i’ll give my two cents on the need for multicloud redundancy or maybe the lack of it.
The tech
In our community, a concept is not real until it has a tool to go with it. Usually more than one as well. Chaos engineering is no exception. As it has existed for a while, multiple tools have been developed and you are free to choose whatever suits your needs. Many of these tools come from internal developer platforms, which later has created a logo, a new name and added an open source license to it. There is nothing wrong with that, tools are made for a purpose and no shoe fits all.
Common for all the tools is that they in some way or another inject failure into your system in a controlled manner, such that we can observe and learn.
The environment
To get some practical experience with Chaos Engineering and the tools that exist we need a realistic environment. Ideally a copy of a production environment, but as i don’t have a production environment at home, we will have to settle for a small lab environment in my own tenant.
The infrastructure
To build a functioning lab we need to scope out what we need. In my case i decided that running a two kubernetes clusters in Azure, alongside a PostgreSQL as a service would do the trick.
We also need a way to access services in both clusters as a unified service. I could use native azure services for this purpose, but my lab is already totally ingrained in CloudFlare, so it was easier to continue using that. Lastly we need a client that can connect to the services and observe the results.
The engine
As i am an Azure-man, and most of my day to day tasks are related to this cloud provider, I felt it was natural to use what tools were available to me in this environment.
Funny enough, since i ended up not using the build-in tooling at all, but ill get back to this later.
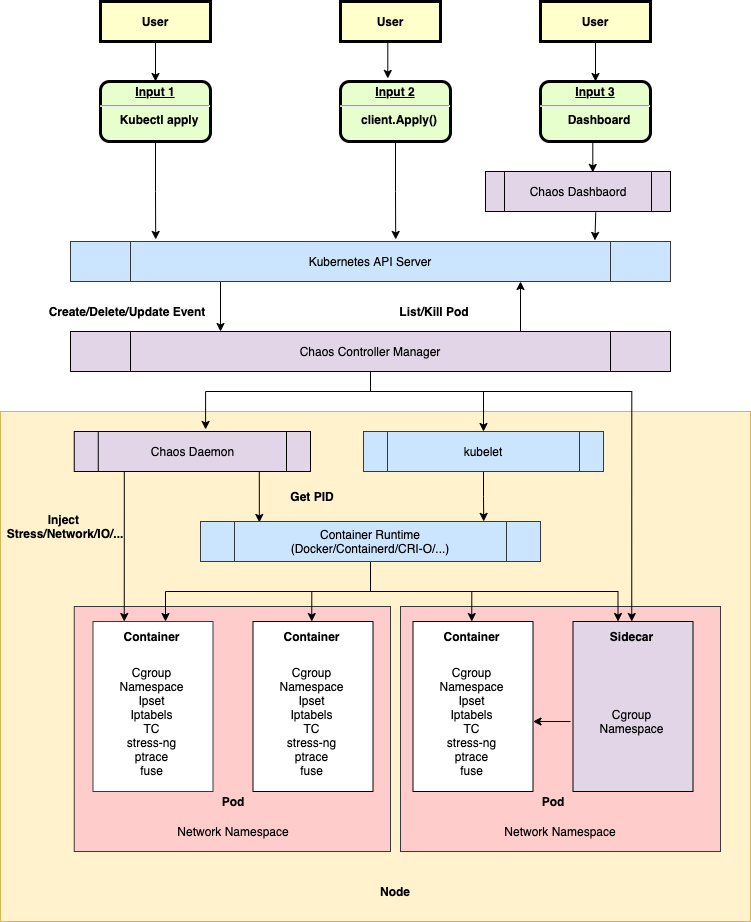
The engine in question is Chaos Mesh, backed by Chaos Studio in Azure. Chaos Mesh is a software in the incubation phase of the CNCF, and is a tool for orchestrating chaos experiments on Kubernetes. With Chaos Mesh you can simulate common faults in your Kubernetes cluster, such as network partition, pod deletion and resource exhaustion. It works in the same way as many other kubernetes tools, using the controller pattern and CRDs to define the experiments. It also deploy daemonsets to inject faults into the container runtime of the pods.
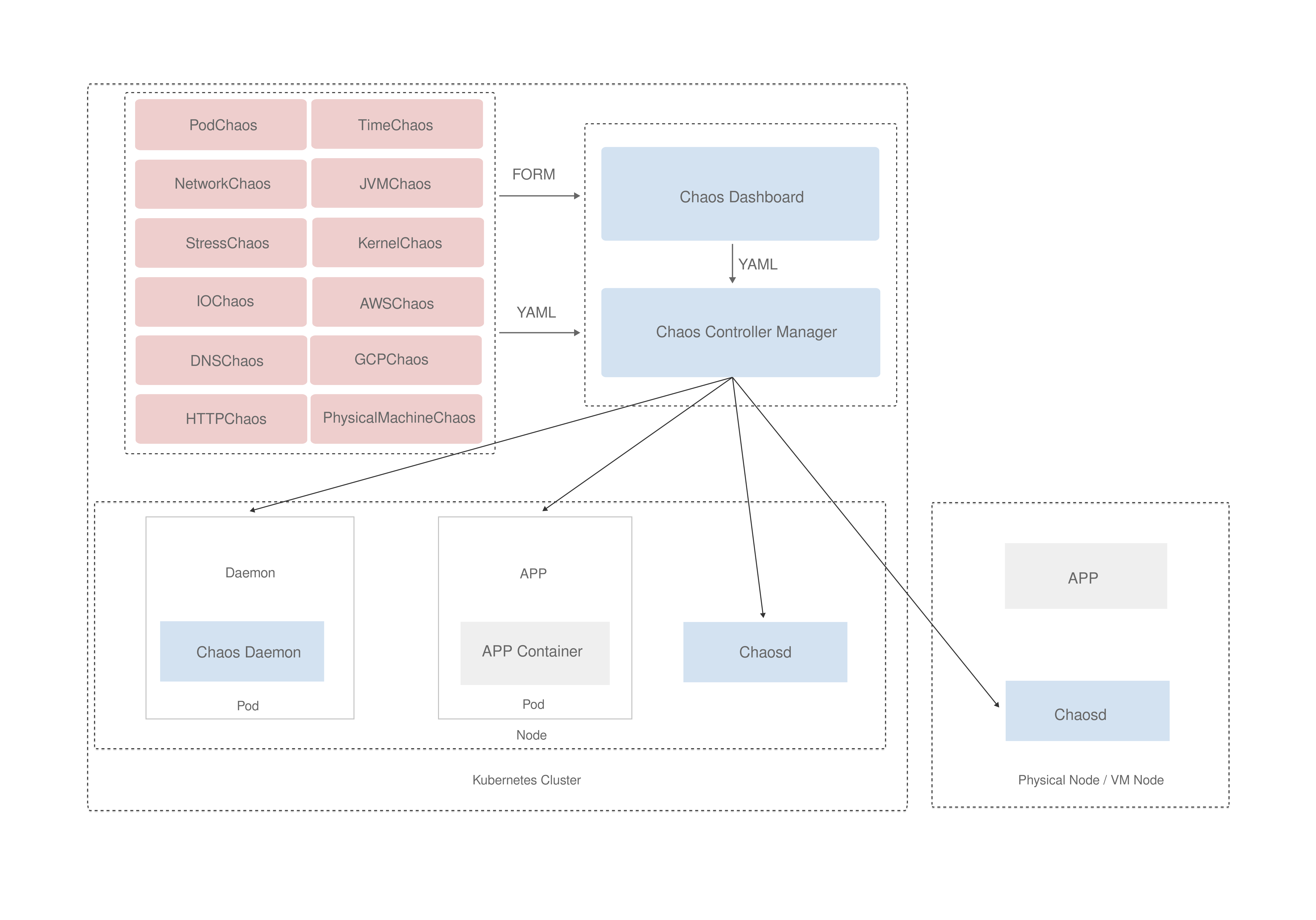
You can use Chaos Mesh in different ways, the deployment comes included with a web interface, Chaos Dashboard. This is a web-based UI that allows you to create, manage and monitor chaos experiments. You can also use YAML manifests directly to define the experiments. Azure has integrated with Chaos Mesh through Chaos Studio, which is a managed service that provides a simplified experience for creating and managing chaos experiments. It is built on top of Chaos Mesh and provides a unified experience for creating and managing chaos experiments across multiple clusters.
The plan was to use Chaos Studio to define the experiments, but I must admit that I never got it to work in time. The error messages i got was not very helpful, so i decided that using the YAML manifests through a normal deployment pipeline was the way to go.
In the end I prefer this outcome as it keeps the experience totally platform agnostic. Kubernetes is kubernetes after all.
The experiments
Now that we have a lab running we need a way to test the different experiments. To do this and document the results i wrote a little go application that offers a simple API to test the different scenarios. One endpoint called /ping returns information about the runtime environment where the instance of the application is running. Like the egress ip, pod name, namespace and cluster information. For every request, this information is returned in the response body and is written to the database.
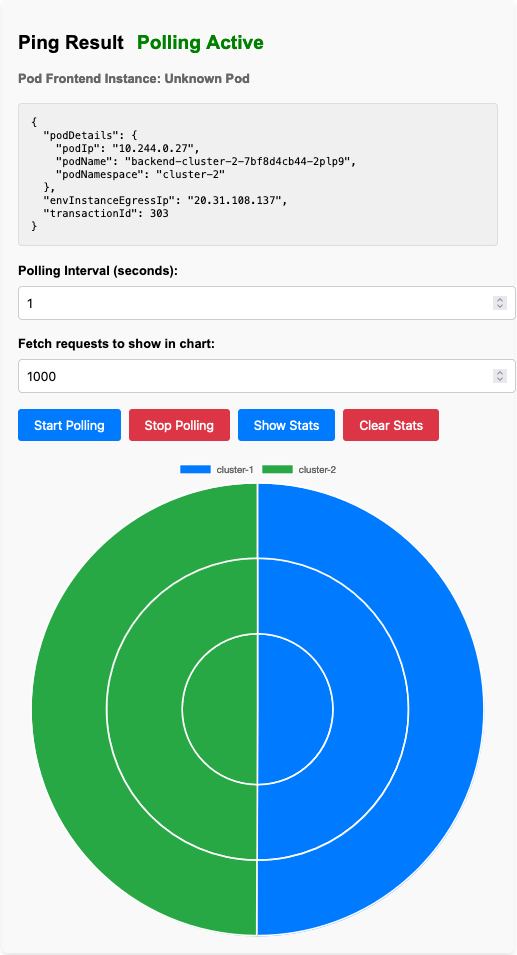
The stat endpoint returns the number of requests each pod has received and how the distribution is between the two clusters and the running pods.
We need some way to show this information in a nice way, so i also wrote a small frontend that shows the information in a pie chart. This frontend is written in SvelteKit and is just hosted locally. It is not very pretty and i had some bugs i could not figure out in time, so you just have to trust me that it works and i’ll explain how the data mapped to each test.
What do we want to achieve?
Simple; how hard is it to get going? How does the injected faults work and will my infrastructure behave as expected?
The tests i have written are not very advanced, and they do not take into account the full scope of what a normal production environment would look like. They are however a good starting point and should give you a good idea of how to get started.
I decided to test these three scenarios:
- Injecting a fault in one of the two clusters
- Injecting faults in both clusters
- Simulate a cloud provider fallout
Injecting a fault in one of the two clusters
In the first test I wanted to see what would happen if we used the included fault in Chaos Mesh called “Pod failure”. I expect that requests will be redirected to the other cluster and that the service will continue to work.
This is how the experiment looks like in the Chaos Studio UI in Azure.
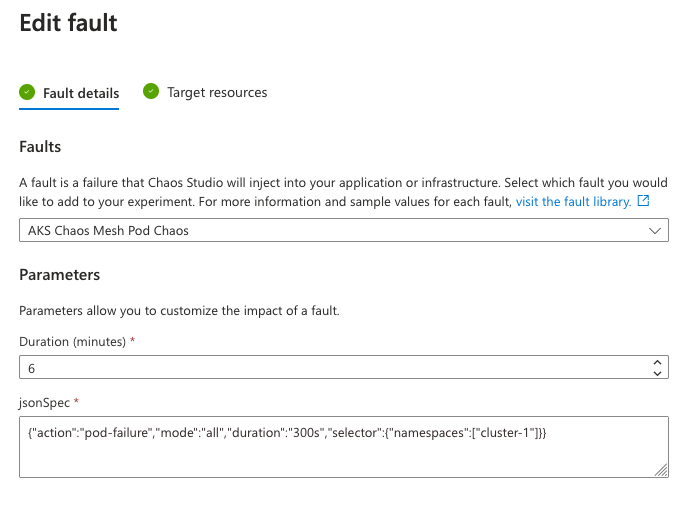
You describe the fault using a json structure, then you choose your target resource and run the experiment. As i mentioned i choose to use a manifest file applied directly in the cluster instead. Luckily there is little difference between the two.
In the manifest you describe basically the same as in Chaos Studio. This is the most minimal example, many more parameters are supported. Among them selectors and randomness for both the targets and the timing.
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-failure
namespace: chaos-testing
spec:
action: pod-failure
mode: all
duration: '600s'
selector:
namespaces:
- cluster-1
When the manifest is applied, the chaos mesh controller will start reconciling the state and inject the fault on the pods in the selected namespace. The fault itself consists of changing the image of the pods to google container pause image, which will make the pods unresponsive. The container looks available, but it will not respond to any requests. When the duration is up, the pods are restored to their original state.
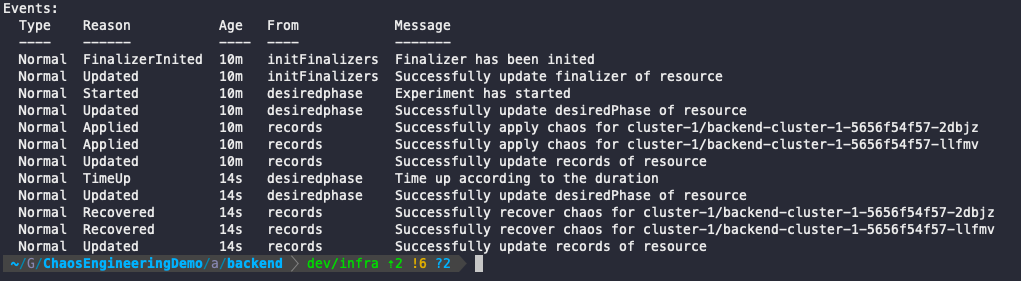
And we can see that while our pods were unresponsive, the service continued to work as expected. The requests were redirected to the other cluster.
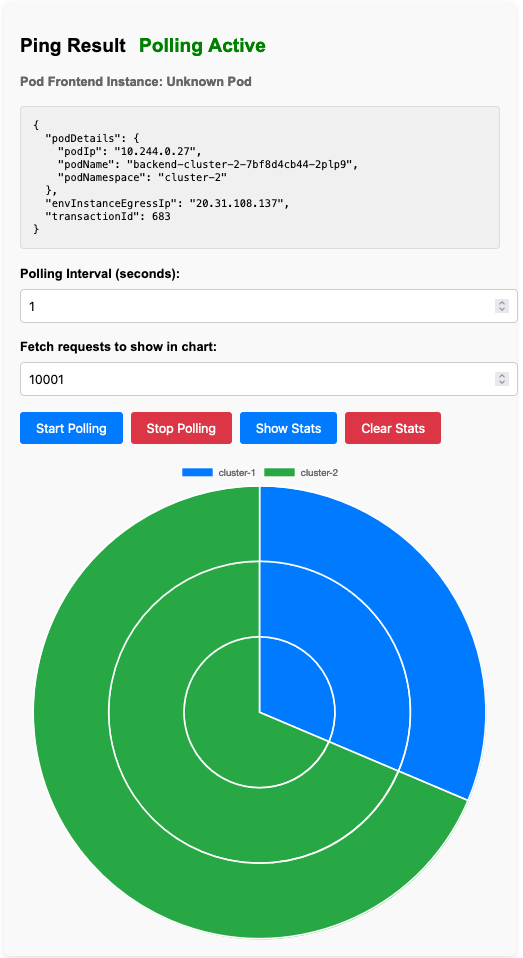
Injecting faults in both clusters
Now that we understand how Pod Failure works, we can try to inject a different fault at the same time in the other cluster. This fault might be more realistic then a pod failure for some of us as it will mimic network issues in the cluster. Usually, from my own experience, network issues tend to occur outside the cluster, but this will give us a good idea of how the service will behave if the network is not reliable.
In this scenario we will introduce latency and jitter in one of the pods in the other cluster. All instances have two replicas, so we should be fine. However, I expect to only see one pod responding to requests while the others are unresponsive. Cloudflare should see that one of its backends are down and redirect the traffic to the other cluster. While kubernetes should detect that one of the pods is very slow to respond and should stop directing traffic to it.
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: delay
namespace: chaos-testing
spec:
action: delay
mode: one
selector:
namespaces:
- cluster-2
delay:
latency: '15ms'
correlation: '100'
jitter: '5ms'
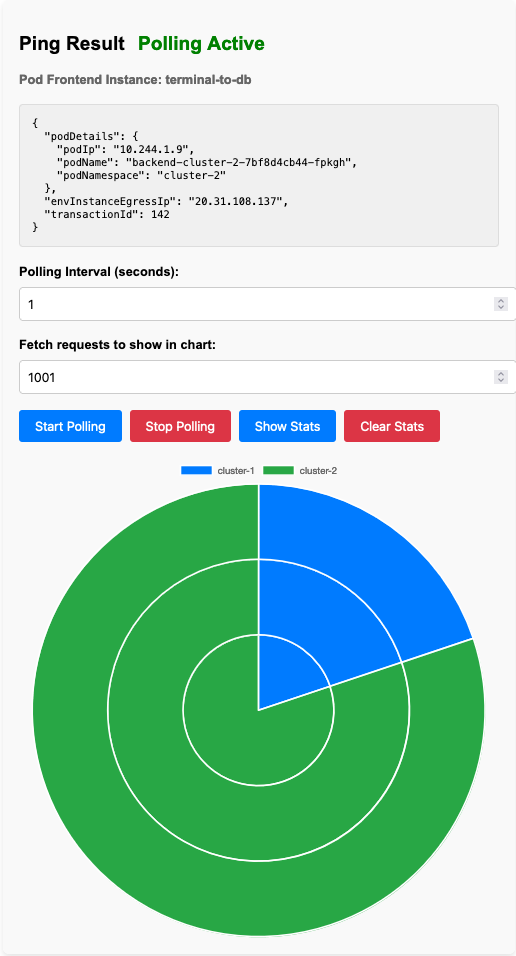
I have to admit that the frontend i wrote did not do a good job of showing the outcome of this test, i found a bug that i could not patch in time of recording, so we have to live with the results and you just have to trust me.
The network fault itself is introduced through the daemonset that runs on the same node as the pod. The daemonset can change the traffic control part of the linux namespace inside the container, adding shaping rules matching what we specify in the manifest. Pretty cool.
This network fault in combination with the previous pod failure resulted in the service being available, but with a higher latency and some timeouts. I was expecting something else, but in the rush to get the presentation ready I forgot to specify the correct liveness and readiness probes in the deployment. The frontend (and the underlying data) show that cloudflare did its job, but inside kubernetes the pod with the network fault was still receiving requests.
Simulate a cloud provider fallout
In the last test I wanted to see what would happen if the cloud provider had a fallout. This is a scenario that is not very likely, and neither was this scenario to be honest. I started removing the lab environment while I had the services running, woops. If my application served static content, I could have utilized the Cloudflare CDN to serve the content for a while, but I did not.
What did we learn?
Now that we have been through a few different scenarios with an expected outcome, which we mostly could confirm, what did we learn?
First, it shows that there is possible to simulate faults we experience in a production environment with little effort. Second, it also gives me confidence that services i build for my team and others will be able to withstand turbulent conditions in production. Lastly, it was inspiring. Maybe i can get my team and other developers to take part in testing like this in a more representative environment. Seeing the consequences of a fault in a controlled environment is a good way to learn how to build more resilient systems.
My application crashing has no consequences of course, it was only a test. But in a real world scenario, the consequences could be severe. Mitigation is usually some form of redundancy or high availability.
High availability vs high cost - Is it worth it?
The question quickly boils down to risk and probability. Even if the application and its dependencies are critical, we know that criticality is expensive. The big cloud providers are painfully aware of this and without taking this seriously they would not have any customers. We have to remember that uptime of our chosen platform is only as good as the services that are built on top. If we look at the big cloud providers and their track record, we see that they are quite good at keeping the lights on.
Historical downtime
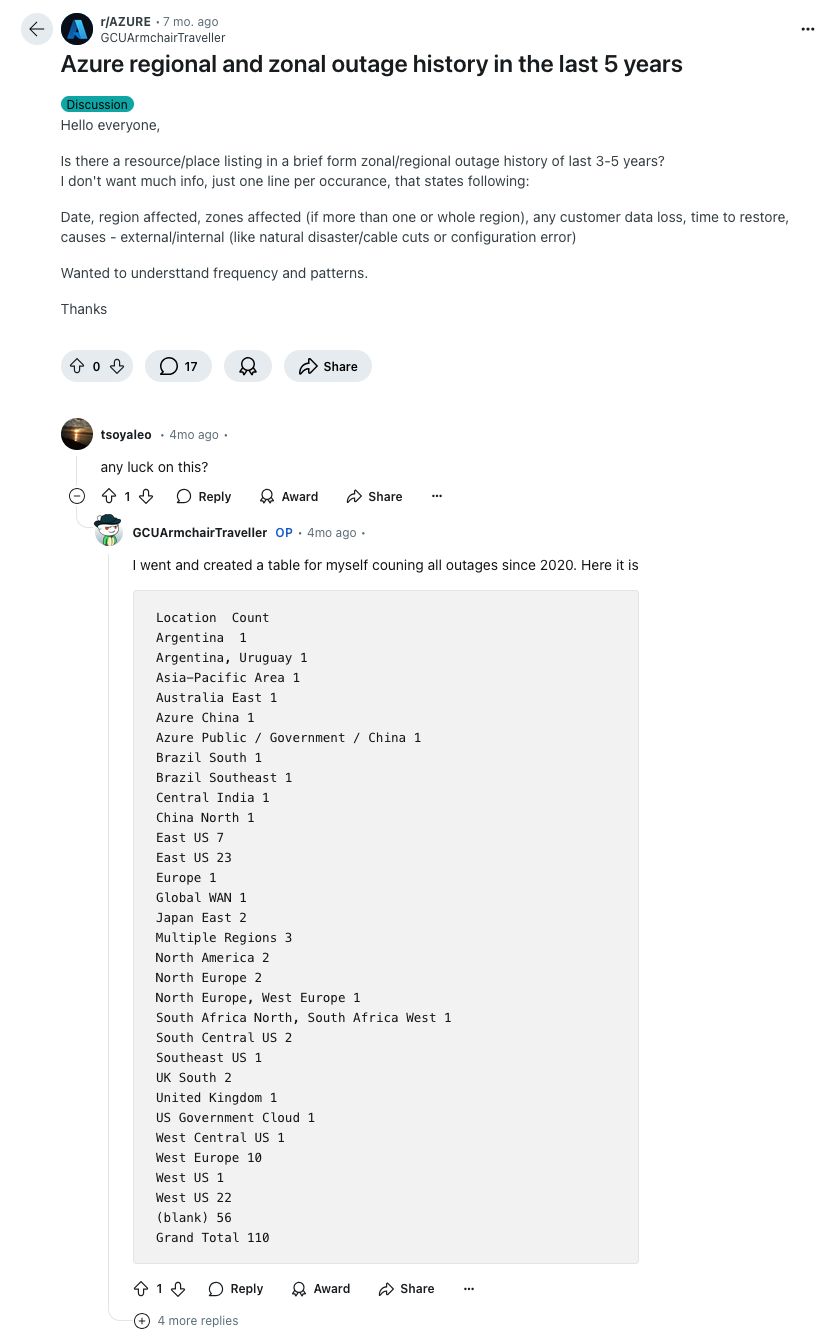
A few nice redditors have looked at all regional outages in Azure since 2019 and its not much. 110 in total. We don’t know how serious all of them were, but from my own experience in Azure since 2019, I cannot recall many occasions where the underlying infrastructure was outright responsible for any major downtime. It does occur , but it is a rare event. What is much more common is human error.
System failure or human error?
We, the engineers responsible for the platform and the services, are the biggest risk to the uptime of the services we provide. We are usually the ones that make mistakes. As an industry we have really good tools to mitigate the risk. The use of infrastructure as code, CI/CD pipelines, testing and having multiple environments are all modern solutions to the problem. It is much harder to do wrong now, but the things that were hard to test still are.
Creating a culture for embracing failure
It’s these faults and errors that really have my interest captured and what inspired me to write this talk. I think there are a few ways to elevate the culture of embracing failure in a company. Here are some examples:
-
Use the tools available With this I mean that we should do even more to prioritize insight through monitoring, logging, tracing and so on. Most of us already have a great stack to work with, but I am certain there are improvements to be made. Enablement, training and workshops are a good way to get started. Generalizing dashboards is a good example. When a developer deploys an application in our environment, we should be able to offer insights from our stack just using the context and metadata provided by the deployment. Giving every developer the same baseline of insight might enable even faster recovery times in an incident.
-
Operations is development For many developers, this might be the most boring topic, especially when feature requests are being forced upon them, but actively participating, owning what you build, and perhaps even contributing to shared components used by others can be highly rewarding. I’m absolutely sure of that. The future is heading towards a more API-driven world regardless, so the skills gap is closing every day. Is it inconceivable that infrastructure could build itself within defined parameters based on needs and source code analysis? The AI revolution is likely here to stay, whether we like it or not.
-
Fail more and fail together It’s great to have test, stage, and pre-prod environments, but these tend to be as stable—if not more stable—than our production environments. Simply because they rarely reflect real-world load or actual complexity. Should we instead focus on emulating failure scenarios we’ve encountered before, or ones we can foresee happening? Looking back at the past two years of post-mortems or incident reports, the services that were affected at the time are often already addressed, but if the issue had occurred slightly differently, with just a small variation, are we confident that the services that worked back then would still hold up now? Chaos Mesh, among others, allows you to integrate test workflows into CI/CD solutions. Perhaps this is a good way to introduce controlled failure? By building standardized workflows that the organization agrees applications running on the platform should be able to withstand we could set requirements. Do you want your application to be categorized as critical? Then you must first guarantee that it meets the uptime requirement.
There’s certainly more we could do, but I believe that these three points, if done right, will have a positive impact on both operations and culture. I’ll have to check back next year to report on the results!
Conclusion
This is the end. Before I go we must talk about multicloud redundancy as I promised in the abstract. I don’t think this is far fetched for most readers. It is more common now to be using multiple cloud providers, especially as they are forking off in both price and service availability. In smaller companies its less common, as maintaining the same governance level and core infrastructure is both expensive and time consuming. Not to mention the competency needed to do so.
The question is if it is worth it? Do you automatically get a more resilient platform by using multiple cloud providers? From my own personal experience we react much more strongly to incidents caused by the cloud provider than incidents caused by our own mistakes. It’s kind of a cognitive dissonance where we accept 99.95% uptime from the cloud provider, which in theory is 4 hours of downtime a year. Then when the cloud provider has downtime, we don’t accept any at all? It is a strange world we live in. I don’t think another dot on the architecture diagram alone will make us more resilient, but I do think that the tools and culture we build around it will.
I believe there are more gains to be made in building a culture for embracing failure and at the same time building more redundancy at the system level. There is no one answer to the question of multicloud redundancy. Think twice about putting the dot on the diagram, it looks cool and it’s fun to say “we are multicloud redundant”, but it might not be the answer.
Should you just have one takeaway from this talk, let it be this: Embracing failure and training for it is important. Probably much more important and cheaper than spinning up extra copies of your infrastructure and applications in someone else’s datacenter.
Thank you for reading this translated version of my talk. I hope I could inspire you to try out Chaos Engineering in your own environment. It is a fun and rewarding experience.
If you have any questions or comments, feel free to reach out to me on Bluesky or LinkedIn.
